
Nowoczesne zarządzanie organizacjami XXI wieku to sprawne i dynamiczne decyzje oparte na zebranych i dobrze przeanalizowanych danych. Coraz to większe potrzeby w zakresie analizy danych związane z wielopłaszczyznową pracą korporacji wymuszają powstawanie nowych hurtowni danych, których budowa staje się coraz bardziej złożona. Tekst ten przedstawia jedną z metodyk projektowych w zastosowaniu do projektowania hurtowni danych. Szczególny nacisk położono na transformacje jakie umożliwia zastosowanie modeli UML z udziałem Common Warehouse Metamodel.
1.Wstęp
Niemal na całym świecie trwają prace nad optymalizacją i ułatwieniem projektowania hurtowni danych. Współczesność wymaga nie tylko rozwiązań skutecznych, ale także bardzo szybkich, niezawodnych i łatwych w obsłudze[3]. Ponadto ciągłe zmiany w organizacji jak i jej otoczeniu wymuszają ciągłe zmiany w strukturze hurtowni. Dodatkowo coraz to większe potrzeby w zakresie analizy danych wymuszają powstawanie nowych hurtowni danych, których budowa staje się coraz bardziej złożona. Wydaje się, że kluczowym dla powodzenia przedsięwzięć projektowania i budowy hurtowni danych oraz zarządzania jej zmianami jest zastosowanie podejścia inżynierskiego stosowanego do tej pory powszechnie w inżynierii oprogramowania. Zastosowanie sprawdzonej metodyki wspomagającej wytwarzanie oprogramowania oraz technik modelowania wizualnego wraz z Common Warehouse Metamodel (CWM) może być dalece pomocne w procesie wytwarzania hurtowni danych. Jedną z takich metodyk powszechnie stosowanych w inżynierii oprogramowania jest Rational Unified Process (RUP), który jest niemalże integralnie związany z językiem modelowania Unified Modeling Language (UML) [4] składnik CWM.
2. Język UML i jego rozszerzenia
Język UML jest zdefiniowany w czterowarstwowej architekturze (cztery poziomy abstrakcji)[6]. Poszczególne warstwy definiują elementy, pojęcia i związki pomiędzy pojęciami. Kolejne warstwy są bardziej ogólne i prezentują się w następujący sposób:
-
warstwa meta-metamodelu (poziom M3) – najbardziej abstrakcyjny poziom;
-
warstwa metamodelu (poziom M2);
-
warstwa modelu (poziom M1);
-
warstwa użytkownika (poziom M0).
Język UML można rozszerzyć przy użyciu stereotypów, skorzystać z rozszerzeń, pakować rozszerzenia za pomocą profili oraz rejestrować cechy elementów modelu.
Stereotyp definiuje typ elementu modelującego w UML. Najpierw należy zdefiniować typ elementu modelującego za pomocą stereotypu, potem można zastosować definicję. Aby utworzyć definicję stereotypu należy przedstawić klasę reprezentującą stereotyp z zależnością od innej klasy reprezentującej typ elementu modelowania, reprezentowanego przez stereotyp. Słowem kluczowym ?stereotype? oznaczamy klasę reprezentującą nowy typ elementu modelującego oraz zależność[5]. Słowo kluczowe ?metaclass? pozwala zdefiniować klasę reprezentującą typ elementu modelującego, do którego stosuje się stereotyp. Nazwę nowego typu należy ująć w symbole << >> lub podwójne nawiasy ostrokątne przed lub nad nazwą elementu modelu.
Własność jest właściwością elementu modelu. Używamy jej do zdefiniowania atrybutów i reguł danego typu elementu modelującego. Do zapisania własności używamy listy łańcuchów tekstowych oddzielonych przecinkami oraz ujętej w nawiasy klamrowe pod nazwą modelu lub po niej. Wszystkie własności mogą być przedstawione w języku komputerowym lub naturalnym. Łańcuch tekstowy może być ograniczeniem lub znacznikiem.
Znacznik jest atrybutem elementu modelu i jego wartością. Definicję znacznika tworzymy przy definiowaniu stereotypu. Zapis jest następujący: nazwa atrybutu, przecinek, typ atrybutu. Znacznik zdefiniowany dla danego stereotypu stosuje się do wszystkich elementów modelu, do których jest zastosowany stereotyp.
Ograniczenie jest regułą, która może np. wskazywać konieczność zakończenia danej czynności przed rozpoczęciem innej. Jest przedstawiane jako łańcuch tekstowy, który można zapisać w języku OCL (ang. Object Constraint Language). Innymi sposobami zapisania ograniczeń są: pseudokod oraz różne języki programowania (m.in. c++, c#, java)[2].
Na profil składają się: definicje znaczników i ograniczeń, definicje stereotypów. Elementy te obowiązują w określonej domenie lub w określonym celu. Profil jest przedstawiany jako pakiet oznaczony słowem kluczowym ?profile?. Dzięki konstrukcji pakietu, na diagramie można pokazać zawartość profilu.
3. Hurtownie danych
Jedną z pierwszych oraz ogólnie akceptowalną definicją hurtowni danych jest ta zaprezentowana przez Billa Inmon w 1991 roku. Według niej hurtownia danych to tematyczna, zintegrowana, zmienna w czasie składnica nieulotnych danych, przeznaczona do wspierania procesów podejmowania decyzji[6].
Hurtownia danych (ang. data warehouse) jest wydzieloną centralną bazą danych zbierającą informacje służące do zarządzania organizacją. Baza ta jest odizolowana od baz operacyjnych, a jej struktura i użyte do jej budowy narzędzia powinny być zoptymalizowane pod kątem przetwarzania analitycznego. W hurtowni są gromadzone dane pozyskiwane okresowo z systemów obsługujących dane operacyjne.
Każda poprawnie skonstruowana hurtownia danych powinna składać się z następujących elementów[3]:
-
narzędzi do ekstrakcji, przekształcania i ładowania danych (ang. Extraction, Transformation, Loading – ETL).
-
warstwy przechowywania danych.
-
warstwy obsługującej zapytania użytkowników.
-
narzędzi udostępniających interfejs użytkownika.
ETL jest to proces wyboru danych ze źródła (systemu źródłowego) następnie przetworzenie oraz załadowanie tych danych do hurtowni. Przykładem może być DTS (ang. Data Transformation Services) używany w środowisku MS SQL Server, dzięki któremu można zintegrować dane z dowolnych źródeł[1].
W hurtowniach danych przechowuje się dane różnych rodzajów:
-
elementarne – kopie aktualnych danych źródłowych pozyskanych z baz operacyjnych i odpowiednio przetworzonych,
-
zmaterializowane agregaty – czyli wyliczone wartości obliczeń, w różnych przekrojach (np. sumy wartości sprzedaży w jednostkach czasu i w podziale terytorialnym) i na różnych stopniach agregacji (np. sumy dzienne, miesięczne, roczne),
-
historyczne – dane elementarne i/lub agregaty dotyczące przeszłości,
-
metadane – informacje słownikowe, opisujące strukturę hurtowni danych i źródłowych baz danych, z których pozyskuje się dane do hurtowni, oraz sposób wyliczania danych zagregowanych.
Cykl życia danych w hurtowni wygląda przeważnie następująco[2]:
-
ładowanie i scalanie – dane są okresowo ładowane z baz operacyjnych. W czasie ładowania dokonywane jest scalenie i ujednolicenie danych, tzn. konwersja typów danych i formatów, przetłumaczanie identyfikatorów, przekształcenie do innego modelu danych,
-
agregacja – od razu w czasie ładowania albo zaraz po nim dokonuje się wyliczenia zmaterializowanych agregatów,
-
przeniesienie do danych historycznych – zanim załadowana zostanie nowa wersja danych elementarnych, dotychczasowe dane muszą być zapamiętane jako historyczne. Nie są one jednak przenoszone do osobnego archiwum, ale są na ogół przechowywane w tej samej hurtowni danych, by możliwe było sprawne dokonywanie porównań i przekrojów czasowych,
-
usuwanie – nie jest operacją typową dla hurtowni, jest przeprowadzane rzadko albo nigdy. Usuwanie może wystąpić, gdy dane historyczne są tak stare, że już nie są wykorzystywane lub, gdy przebudowuje się hurtownie i zmienia ona swoje zadania.
Właściwości hurtowni danych odróżniające je od innych rozwiązań opartych na bazach danych:
-
wielowymiarowa perspektywa koncepcyjna,
-
ogólna wielowymiarowość,
-
nieograniczone operacje między wymiarami,
-
nieograniczone wymiary i poziomy agregacji,
-
architektura klient-serwer,
-
obsługa jednoczesnego dostępu wielu użytkowników,
-
dynamiczna obsługa rzadkich macierzy,
-
dostępność,
-
intuicyjny interfejs manipulowania danymi,
-
elastyczność generowanych raportów,
-
spójny mechanizm raportowania,
-
przezroczystość.
3.1 Model logiczny hurtowni danych
Model logiczny hurtowni danych składa się z elementów: fakt, wymiar, atrybut, miara.
Fakty ? zmienne analizowane.
Wymiary ? zmienne pozwalające na grupowanie danych, są analizowane.
Atrybut – podstawowa jednostka opisu modelu, może wyznaczać inne atrybuty oraz być wyznaczany. Atrybuty posiadają zbiór przyjmowanych wartości, np. atrybut godzina może przyjmować wartość 11.
Miara ? wartość liczbowa przyporządkowana do jakiegoś faktu (liczba sztuk, wartość sprzedaży).
Można go przedstawić w 2 podstawowych schematach: gwiazdy oraz płatka śniegu.
Schemat gwiazdy wykorzystuje tabelę faktów otoczoną tabelami wymiarów. W tabeli faktów znajdują się mierzalne fakty połączone za pomocą kluczy z tabelami wymiarów. W tabelach wymiarów znajdują się opisy wymiarów.
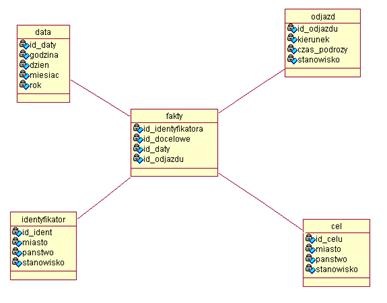
Rys. 1. Przykład logicznego schemat hurtowni danych (opr. własne)
Schemat płatka śniegu różni się tym od schematu gwiazdy, że w tabelach wymiarów zapisane są identyfikatory wymiarów nadrzędnego i podrzędnego poziomu. Rozwiązanie to ułatwia operacje selekcji danych związanych z wymiarami oraz pozwala na dokładniejsze uchwycenie hierarchii atrybutów[6].
Architekturę hurtowni danych można podzielić na następujące rodzaje:
-
scentralizowana;
-
warstwowa;
-
federacyjna.
W scentralizowanej architekturze dane analizowane w przedsiębiorstwie są przechowywane w jednej hurtowni danych.
Zaletami tego rozwiązania są:
-
uproszczenie dostępu do danych dzięki ujednoliceniu ich modelu;
-
budowa oraz konserwacja takiej hurtowni jest dużo prostsza od systemu rozproszonego
-
jest najbardziej odpowiednią formą stosowaną w instytucjach, w których działalność operacyjna jest scentralizowana.
W architekturze warstwowej hurtownia globalna jest rzeczywistą, fizyczną bazą danych. Hurtownia globalna jest uzupełniana kolejnymi poziomami lokalnych, tematycznych hurtowni danych.
Architektura federacyjna zawiera dane logicznie jednorodne, które są przechowywane fizycznie w innych bazach danych znajdujących się w jednym lub paru systemach komputerowych. Każdy dział instytucji zawiera lokalne tematyczne hurtownie. Umożliwia to analizowanie lokalne na różnych poziomach szczegółowości[4].
Istotną rolę w budowie i działaniu hurtowni danych odgrywają metadane. Są one przechowywane w wydzielonej bazie, do której dostęp posiadają wszystkie inne składniki hurtowni. Baza metadanych może zawierać następujące elementy:
-
informacje o poszukiwanych przez użytkowników danych
-
słowniki danych (definicje baz danych oraz relacji między elementami)
-
informacje o transformacji danych (wykonanie podczas przenoszenia)
-
numery wersji przechowywanych metadanych
-
nazwy nadane poszczególnym polom w bazie
-
informacje o przepływie danych
-
statystyki użycia danych (profil danych)
-
uprawnienia użytkowników
3.2 Rozszerzenie dla hurtowni danych
Aby umożliwić łatwą wymianę meta-danych pomiędzy narzędziami, platformami oraz repozytoriami hurtowni danych, w rozproszonych heterogenicznych środowiskach, opracowano CWM (ang. Common Warehouse Metamodel). CWM opiera się na następujących standardach opracowanych przez OMG[8]:
-
UML;
-
MOF (ang. Meta Object Facility);
-
XML.
Standard MOF definiuje rozszerzalną strukturę dla definiowania modeli metadanych. Dostarcza też narzędzi programistycznych pozwalających na przechowywanie i dostęp do meta-danych w repozytorium.
XML pozwala na wymianę danych w postaci standardowych plików XML.
Kluczowymi aspektami takiej architektury są:
-
czterowarstwowa architektura meta-modelu służąca do manipulacji metadanymi w rozproszonych repozytoriach;
-
reprezentacja meta-modeli oraz modeli przy użyciu notacji UML;
-
użycie standardowych modeli UML do opisu semantyki analizy obiektów oraz modeli projektowych;
-
zastosowanie MOF do definiowania i manipulacji meta-modelami przy użyciu interfejsu CORBA (ang. Common Object Request Broker Architecture);
-
wykorzystanie XML do strumieniowej wymiany metadanych.
4. Projektowanie hurtowni danych
XML jest używany do wymiany metadanych (opartych na meta-modelu CWM) z hurtowni danych. Meta-model CWM jest opisany przy użyciu modelu MOF (ang. Meta Object Facility), który pozwala na użycie XML do:
-
transformacji meta-modelu CWM do pliku CWM DTD;
-
transferu instancji metadanych hurtowni (jeśli spełniają kryteria meta-modelu CWM) do dokumentów XML opartych na CWM DTD;
-
transformacji meta-modelu CWM na dokument XML.
Podczas użycia wszystkich powyższych wytycznych można wymieniać metadane hurtowni za pomocą XML.
4.1 Meta Object Facility
MOF służy do definiowania metadanych oraz do reprezentacji tych danych jako obiekty CORBA. Wspiera te rodzaje metadanych, które można opisać przy użyciu technik modelowania obiektowego. Metadane mogą opisywać dowolny aspekt systemu oraz zawierane inne dodatkowe informacje. Nie ma ograniczeń co do stopnia szczegółowości ani precyzji opisu.
Model wg MOF jest zbiorem metadanych, spełniających wymogi struktury oraz zgodności (posiadających abstrakcyjną składnię).
Metadane są rodzajem informacji. Jeśli opiszemy je za pomocą metadanych powstaną meta-metadane (wg terminologii MOF). Model zawierający meta-metadane jest nazywany meta-modelem[9].
Meta-model MOF definiuje wiele rodzajów metadanych, dlatego powstała czterowarstwowa architektura (o której wspomniałem już w rozdziale ?Rozszerzenia UML?) pokazana w tabeli niżej.
Tabela 1. Architektura Metadanych wg OMG[8]
|
Poziom Meta |
termin MOF |
Przykład |
|
M3 |
meta-metamodel |
Model MOF |
|
M2 |
metamodel, meta-metadane |
UML Meta-model, CWM Metamodel |
|
M1 |
model, metadane |
Modele UML, Metadane CWM |
|
M0 |
obiekt, dane |
dane w hurtowni, modele systemów |
Model MOF może być traktowany jako abstrakcyjny język służący do opisu meta-modeli MOF. Trzy główne elementy modelowania metadanych dostarczone przez MOF, podobne do elementów UML, lecz bardziej uproszczone, to: klasa, asocjacja oraz pakiet:
-
Klasy mogą posiadać atrybuty i operacje na dwóch poziomach: obiektowym i klasowym. Mogą wielo-dziedziczyć po innych klasach.
-
Asocjacje pozwalają na binarne połączenie instancji klas. Każda asocjacja posiada dwa „końce”, które mogą posiadać inne symbole.
-
Pakiety są zbiorem powiązanych klas i asocjacji. Pakiety mogą być tworzone poprzez import innych pakietów lub poprzez dziedziczenie po nich. Pakiety można także zagnieżdżać.
Kolejnymi ważnymi elementami modelu MOF są ograniczenia i typy danych:
-
Ograniczenia są używane do połączenia znaczeniowych restrykcji. Do ich zapisu można używać dowolnego języka.
-
Typy Danych umożliwiają stosowanie typów nie obiektowych jako atrybutów lub parametrów.
Kolejnym ważnym składnikiem MOF jest IDL Mapping. Jest to zestaw szablonów pozwalających zamienić metamodel MOF w zbiór interfejsów CORBA IDL. Mapowanie IDL jest bardzo obszernym zagadnieniem. Ważnymi tu informacjami, ze względu na istotę pracy, są:
-
klasa w metamodelu występuje jako interfejs IDL, który wspiera operacje, atrybuty oraz referencje zdefiniowane w meta-modelu;
-
asocjacja występuje jako interfejs, wspierający zapytania asocjacyjne;
-
pakiet staje się interfejsem przechowującym procedury dla klas i asocjacji.
MOF jest standardem OMG służącym reprezentacji metamodeli. Metamodel CWM został stworzony w oparciu o te standardy. Dzięki temu można używać XMI do wymiany metadanych z hurtowni (zapisanych w CWM).
4.2 Common Warehouse Metamodel
CWM służy do definiowania metamodelu architektury hurtowni danych. Zawiera także formalne zasady modelowania instancji hurtowni danych. Metamodel CWM musi być zapisany w MOF (wymiana poprzez CORBA lub XMI). Meta-model CWM zawiera pakiet modelu obiektowego, opartego o metamodel UML. Meta-model UML został w tym przypadku pozbawiony aspektów niezwiązanych z hurtowniami danych. Meta-model CWM jest rozszerzeniem modelu obiektowego opartego na UML. Każda meta-klasa w CWM dziedziczy po meta-klasie z modelu obiektowego. Notacja UML jest także używana w diagramach reprezentujących meta-model CWM.
CWM używa XMI jako mechanizmu wymiany. Oznacza to, że można korzystać ze wszystkich możliwości XMI podczas przenoszenia meta-danych hurtowni oraz meta-modelu CWM. Po za tym CWM nie potrzebuje dodatkowych rozszerzeń XMI.
Metadane hurtowni mogą być zapisywane jako dokumenty XML przy użyciu zasad tworzenia dokumentów XMI.
Metamodel CWM korzysta z pakietów oraz hierarchicznej struktury aby kontrolować złożoność, ułatwić zrozumienie i ponowne użycie. Elementy modelu są zawarte w następujących pakietach[1]:
-
Pakiet Modelu Obiektowego
-
Pakiet główny (rdzeń) – zawiera klasy oraz asocjacje, tworzące rdzeń modelu obiektowego CWM. Są one używane przez wszystkie pakiety CWM włącznie z pakietami modelu obiektowego;
-
Pakiety behawioralne – zawierają klasy i asocjacje, które opisują zachowanie obiektów CWM. Dostarczają podstaw do opisu wywołania zdefiniowanych zachowań;
-
Pakiet powiązań – zawiera klasy i asocjacje opisujące związki między obiektami CWM;
-
Pakiet instancji – obejmuje klasy i asocjacje reprezentujące instancje klasyfikatorów CWM;
-
-
Pakiet Podstawowy
-
Pakiet informacji biznesowych – należą do niego klasy oraz asocjacje odnoszące się do biznesowych informacji opisujących elementy modelu;
-
Pakiet typów danych – zawiera klasy i asocjacje opisujące konstrukcję, której należy używać podczas tworzenia potrzebnych typów danych;
-
Pakiety wyrażeń – obejmują klasy i asocjacje przedstawiające drzewa wyrażeń;
-
Pakiety kluczy oraz indeksów – należą do nich klasy a także asocjacje reprezentujące klucze i indeksy;
-
Pakiety rozmieszczenia oprogramowania – zawierają klasy i asocjacje opisujące sposób rozmieszczenia oprogramowania w hurtowni danych;
-
Pakiet mapowania typów – opisuje klasy i asocjacje przedstawiające mapowanie typów danych pomiędzy różnymi systemami;
-
-
Pakiet Źródłowy
-
Pakiet relacyjny – zawiera klasy i asocjacje posiadające metadane o danych relacyjnych;
-
Pakiet rekordów – przedstawia klasy oraz asocjacje reprezentujące meta-dane o rekordach;
-
Pakiet wielowymiarowy – posiada klasy oraz asocjacje opisujące meta-dane o wielowymiarowych danych;
-
Pakiet XML – zawiera klasy oraz asocjacje przedstawiające metadane o danych XML;
-
-
Pakiet Analizy
-
Pakiet transformacji – zawiera klasy i asocjacje reprezentujące meta-dane o narzędziach transformacji danych;
-
Pakiet OLAP (ang. On Line Analytical Processing) – posiada klasy oraz asocjacje przedstawiające metadane o oprogramowaniu wspierającym podejmowanie decyzji;
-
Pakiet drążenia danych – opisuje klasy i asocjacje reprezentujące meta-dane o oprogramowaniu do drążenia danych;
-
Pakiet wizualizacji informacji – zawiera klasy oraz asocjacje, które reprezentują metadane o narzędziach do wizualizacji informacji;
-
Pakiet nomenklatury biznesowej – klasy i asocjacje przedstawiające meta-dane o słownictwie biznesowym;
-
-
Pakiet Zarządzania
-
Pakiet procesów hurtowni – zawiera klasy i asocjacje reprezentujące metadane procesów hurtowni danych;
-
Pakiet operacji hurtowni – przedstawia klasy oraz asocjacje opisujące metadane o wynikach operacji hurtowni danych;
-
4.3 Wielowymiarowość
Wielowymiarowa hurtownia danych jest reprezentowana przez wielowymiarowy meta-model CWM. Nie daje on pełnego odwzorowania wszystkich aspektów wielowymiarowości, lecz daje solidny szkielet, który z łatwością można poszerzyć wedle własnych potrzeb[2].
Ta wielowymiarowość jest oparta o następujące pakiety:
-
org.omg::CWM::ObjectModel::Core
-
org.omg::CWM::ObjectModel::Instance
Klasy i asocjacje wielowymiarowego meta-modelu przedstawiono na (rys. 2).
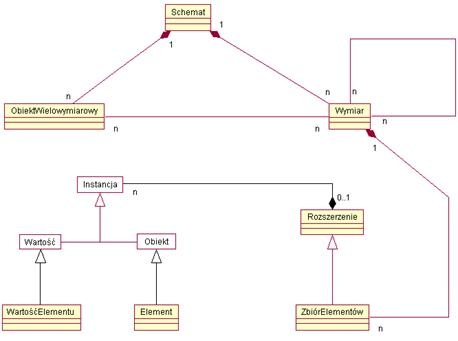
Rys. 2. Wielowymiarowy meta-model: Klasy i Asocjacje, opracowano na podstawie Common Warehouse Metamodel Specification[10]
Schemat zawiera wszystkie elementy składające się na wielowymiarową bazę. Wymiar reprezentuje fizyczny wymiar bazy. Wymiar może posiadać referencje do innych wymiarów, co pozwala na utworzenie złożonych struktur wielowymiarowych. Obiekt wielowymiarowy reprezentuje atrybut wymiaru. ZbiórElementów oznacza zespół elementów powiązanych z instancją wymiaru. Wartość ZbioruElementów oznacza WartośćElementu.
5. Projektowanie hurtowni danych w oparciu o RUP
Rational Unified Process jest złożoną metodyką, którą można dostosować do prawie każdego przedsięwzięcia. Sprzyjają temu celowi takie narzędzia jak Rational Method Composer[9]. Poniżej przedstawiony skrócony wykaz czynności według RUP wspomagający wytworzenie hurtowni danych[2].
Model wymagań:
-
utworzenie wymagania typu Przypadek Użycia w RequisitePro;
-
dokonanie asocjacji repozytorium modeli opisowych z repozytorium modeli graficznych wskazując odpowiedni pakiet obejmujący (w Rational Rose);
-
tworzenie diagramu przypadków użycia wybierając usługi z dostępnych usług wcześniej opracowanych w modelu opisowym;
-
dodanie do modelu aktorów oraz relacji;
-
wykonanie walidacji modelu;
-
stworzenie głównych scenariuszy dla wszystkich usług (oraz wybrane scenariusze alternatywne) na diagramach sekwencji;
-
transformacja diagramu sekwencji w diagram współpracy;
Model analizy:
-
identyfikacja klas:
-
karty CRC;
-
analiza lingwistyczna;
-
metody eksperckie;
-
-
po zakończeniu identyfikacji dokonanie analizy obiektów występujących w scenariuszach;
-
tworzenie definicji klas;
-
utworzenie związków pomiędzy klasami;
-
dokonanie analizy związków bezpośrednich dla modelu klas przez analizę diagramów współpracy (m.in. technika krzyżowa);
-
określenie realizacji dla przypadków użycia;
-
przeniesienie realizacji przypadków użycia do Logical View;
-
przekształcenie modelu klas w model klas analitycznych;
-
dla każdej realizacji przypadku użycia utworzenie:
-
diagramu VOPC;
-
klas granicznych (tyle, ile aktorów korzysta z usługi (przypadku użycia));
-
jednej klasy sterującej;
-
klas danych;
-
-
uzupełnienie definicji klas i specyfikacji związków;
-
-
uzupełnienie scenariuszy o nowe obiekty;
Model projektowy:
-
stworzenie komponentu hurtowni danych (wskazując jej docelowy motor);
-
utworzenie przestrzeni roboczych (fizyczne obszary alokacji zasobów hurtowni);
-
utwardzenie klas danych (tylko tych, które będą przekształcone w tabele);
-
wykonanie modelu danych:
-
wskazanie pakietu obejmującego klasy utwardzone;
-
utworzenie schematu hurtowni;
-
transformacja klas w model danych;
-
zbudowanie diagramu danych;
-
-
przypisanie istniejącym tabelom przestrzeni roboczej;
-
generowanie hurtowni danych przy użyciu inżynierii w przód;
-
dokonanie koniecznych zmian po stronie kodu hurtowni;
-
synchronizacja kodu z modelem bazy.
Zakończenie
W niniejszej pracy przedstawiono poziomy abstrakcji języka UML. Dokonano analizy mechanizmów umożliwiających łatwą wymianę metadanych pomiędzy narzędziami, platformami oraz repozytoriami hurtowni danych. na Dokonano typologii procesów wytwórczych hurtowni danych oraz procesów jej utrzymania. Wskazano także na szereg transformacji jakie zachodzą między metamodelami i meta-metamodelami, dzięki którym można przedstawić hurtownię danych na kilku poziomach abstrakcji. Wynikiem tych transformacji jest opracowany proces wytwarzania hurtowni danych w oparciu o znany proces wytwarzania oprogramowania ? RUP. Podsumowując zaprezentowany meta-model CWM pracujący w heterogenicznych środowiskach wraz UML i przy udziale metodyki RUP stanowi jedno potężniejszych rozwiązań pozwalających na wydajne projektowanie i budowę hurtowni danych.
Literatura
2. Ambler S.W. : A RUP-based approach to developing a data warehouse. IBM DeveloperWorks, (14.01.2008)
3. Barczak A., Florek J., Sydoruk T.: Bazy danych. Wydawnictwo AP, Siedlce 2006
5. Dąbrowski W., Stasiak A., Wolski M.: Modelowanie systemów informatycznych w języku UML 2.1,Wydawnictwo Naukowe PWN, Warszawa 2007 r. ISBN: 978-83-01-15251-2
6. Inmon W. H.: Building the Data Warehouse. Wiley Publishing INC, Indianapolis, 2005
7. Kimball R. , Caserta J.: The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleanin, Wiley Publishing INC, Indianapolis, 2004
8. The Object Management Group (OMG) www.omg.org
10. Common Warehouse Metamodel (CWM) Specification v 1.1 formal/2003-03-02
11. UML Infrastructure Specification- UML Version 2.1.2 – formal/2007-11-02
12. UML Superstructure Specification- UML Version 2.1.2 – formal/2007-11-04
